A Web App for Level-Sensitive Vocabulary Acquisition Using YouTube Playlists in JFL
第76回 ことば工学研究会 2025年3月28日
はじめに
背背景
ある対象を理解するためにどのようなコトバがつかえるといいのか
あるコミュニティで使われているコトバの意味はどのように推定できるか
特定目的のための日本語教育 | JSP(Japanese for Specific Purposes)
JSP:職業目的の日本語、アカデミック日本語、など
⇔ 一般目的のための日本語教育(日本語能力試験)
今回のシステム
・特定目的のための日本語教育を支援するツール
・YouTubeを教材として、そのYouTubeを理解するための語彙を学習する
言語学習の教材の条件(田中)
『幼児から成人まで一貫した英語教育のための枠組み』(共著、リーベル出版、2005年)
①language exposure の質量 (言語に触れる質量)
②language use の質量
③urgent need の存在
meaningfulで、authenticで、そしてpersonalな教材の提示
一般的な教材:教え手側が学習段階に応じて教材を提示する
本システムの教材:学び手側が興味に応じて学習素材を選択する
「日本語学習者」の定義
日本語学習者数は主として国内については文科省(文化庁)、国外については国際交流基金(JF)が調査を実施している
「日本語学習者」とは日本語を学ぶ者のことを、「受講者」とは日本語教師等の養成・研修の講座を受ける者のことを指している。
令和5年11月1日現在、国内における日本語教育実施機関・施設等数は2,727、日本語教師等数は46,257人、日本語学習者数は263,170人となっている。
文科省が令和5年度調査において示している日本語学習者は図に示す通りである。ここで日本語学習者数とされているのは「日本語教育を実施していると回答した機関等並びに当該機関等に所属する教師等数、日本語学習者数」であり、機関に所属していない学習者は含まれていない
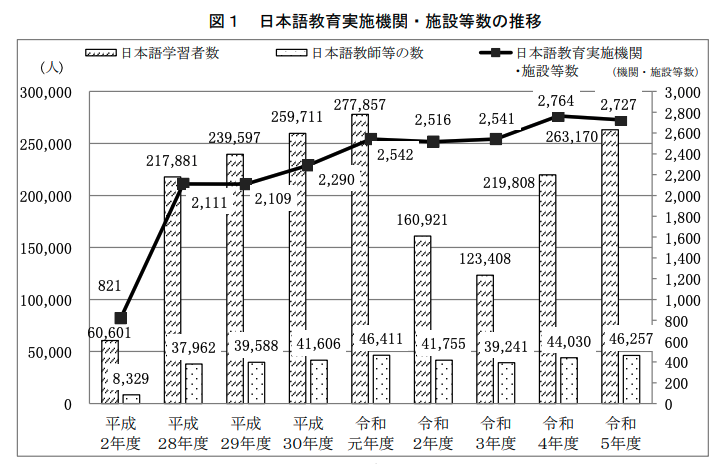
したがってコロナ期間の渡航者減少の影響を色濃く反映しており、「令和2年度から5年度にかけて123,408人から263,170人と、日本語学習者は2倍以上増えている」という読み方は適切ではない。
国際交流基金の実施による2024年度調査は現在実施中であるため、公表されている結果は2021年度海外日本語教育期間調査が最新である。2021年度の日本語学習者は 調査対象は海外で日本語教育を実施している可能性のある機関である*1
[1] 以下は調査対象ではないとされている。
①組織としての実体を伴わない団体(活動)
②在留邦人子弟向けの日本人学校・調査時点で文部科学省が認可する補習授業校 ※各国の日系子女を対象に外国語として日本語教育を行う機関は対象とする。
③不特定多数を対象に日本語教育を行っている放送局やWebサイト管理者
④短期的な日本語体験活動。
国外の「日本語学習者」は380万人 The number of learners: 3.8million
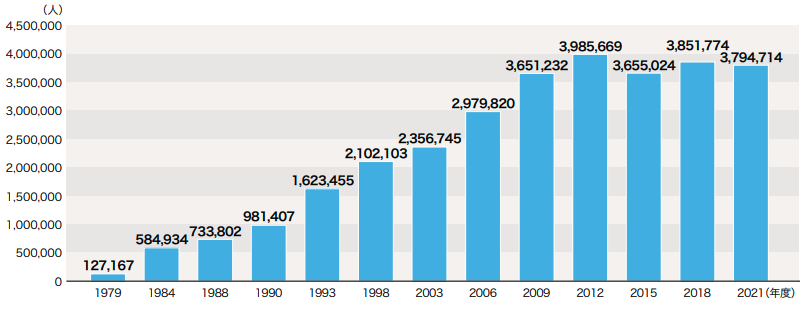
Number of institutions: 18,272 (second highest ever)
Number of teachers: 74,592 (2nd highest ever)
Learners: 3,794,714 (3rd highest ever)

結果概要“, Japan Foundation, Dec. 2021
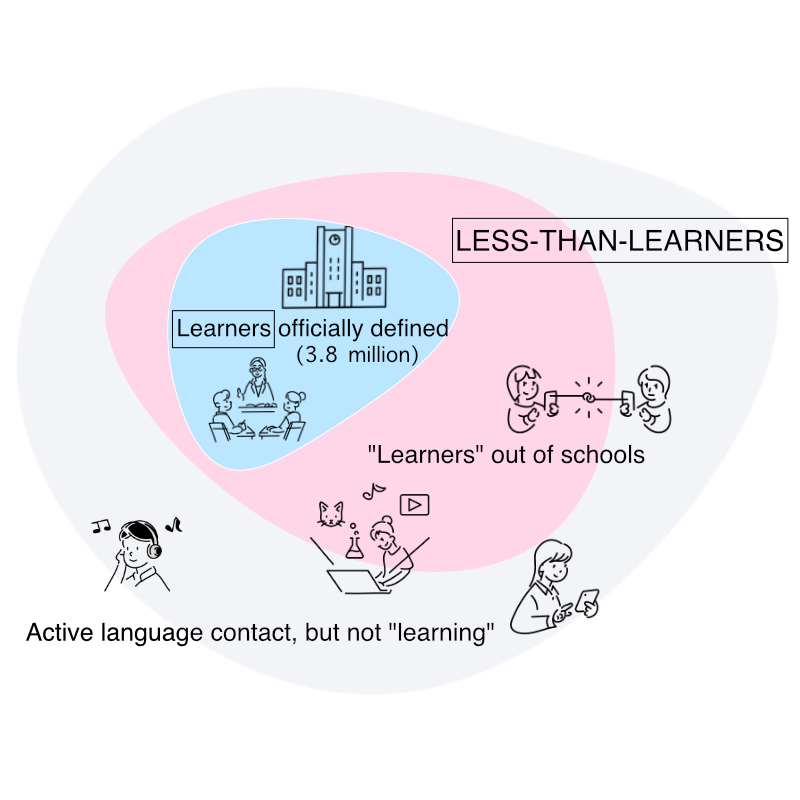
「日本語学習者」ではない、潜在的な日本語学習者
SNSを通じた多言語情報への接触が一般化し、言語学習の動機が多様化している
Motivations for language learning are becoming more diverse as contact with multilingual information through SNS is becoming more common.
したがって、言語教育機関にいる学習者ではない、潜在的な「学習者未満の学習者」が増えていることが予想される
Therefore, it is expected that the number of potential ‘less-than-learners,’ who are not explicit learners in the classroom, is increasing
Less-than-learners
Less-than-learners is my original term, it refers to the learners out of school, and people who actively contact Japanese content.
目的Aim of this study
学習者が自分の好きな日本語のYouTube動画を見て、その動画で使われている語彙や文法を学習できるシステムを提案する
To propose a self-learning system that allows learners to watch their favorite Japanese-language YouTube videos and learn the vocabulary and grammar used in videos.
2.1 YouTubeを活用した自己学習システム
本研究では、初心者や非公式な教育環境にいる学習者が日本語を学習するためのウェブベースの自己学習システムを提案する。システムの概要を図1に示す。
Outlines of the system
INPUT YOUTUBE LINKS → GET A VOCABULARY LIST
This system is planned as a web application.
Learners will select their Japanese level and input links of videos they want to watch.
In order to obtain a sufficient word size for the co-occurrence analysis, it is desirable that the links be entered for approximately 10 videos of 10 minutes in length.
If the video length is for several hours, such as a video of a live game, a single video link would be sufficient in size.
共起分析に十分な語数を得るため、10分の動画10本程度のリンクが入力されていることが望ましい。
ゲーム実況の動画など動画の長さが数時間の場合は、動画リンクは1つで十分な語数となる。

How to use the self-learning system
- Visit the system website
- Select your Japanese language level
- Enter 5-10 links to the videos you want to watch
- Press the [Search] button
- Learn the displayed list of words and grammar list
- Watch the video you want to watch
システム構成
本システムはウェブアプリケーションとして開発されており、バックエンドにはPythonのFlaskフレームワークを利用している。フロントエンドのユーザーインターフェースはHTML、CSS、JavaScriptおよびBootstrapを用いて構築され、様々なデバイスやプラットフォームで直感的かつレスポンシブに動作することを目指した。
再生リストから字幕情報を取得する
本アプリケーションではYouTube Data API v3を使用してユーザーが選択した動画から字幕データを取得する。
バージョン1は動画リンクを10本分入力する仕様である。
バージョン1ではスマートフォン利用時にYouTubeアプリでリンクをコピーしブラウザでペーストする工程が煩雑であった。
この課題を解決するため、バージョン2では再生リストのリンクを入力することで、APIが自動的にリスト内の全動画を展開し字幕データを取得するよう改善した。
再生リストの例
ユーザーは自身で好みの動画から再生リストを作成し、リンクを入力する事もできるし、また公開されている再生リスト(例えばNHKの再生リスト「クローズアップ現代」など)を活用する事もできる。
ただし、動画本数が多くなると動画を分析する時間が長くなり、また学習語彙の提示量が増大するという問題が生じる。動画本数が多い場合に、再生リスト内の動画のうち、学習素材とする動画を選択して分析できるように今後アップデート予定である。
動画字幕情報の処理
取得したテキストデータは日本語自然言語処理ツールMeCabを用いて形態素解析される。
本アプリケーションでは名詞、動詞、形容詞を学習対象語として提示する。
MeCabによる形態素解析時に出力される品詞分類と語彙表に記載された品詞分類が一致していない場合があるため、事前に品詞分類のマッピングを行う。
具体的には、MeCabの出力する詳細な品詞分類を教材用語彙リストの分類基準に合わせるため、例えば『一般名詞』、『サ変名詞』、『形容動詞語幹』など細分化された品詞カテゴリを、教材用語彙リストが採用する『名詞』や『動詞』などの主要品詞カテゴリに統合する。これによって解析後の語彙と教材リストの整合性を保っている。
n-gramによる語抽出
YouTube動画の日本語字幕データに対し、単語レベルでのテキスト解析を行う際に、n-gram に基づく特徴抽出手法を行う。n-gramとは、テキストを連続する n 個の単語や文字列に分割する手法であり、自然言語処理における基本的な手法のひとつである。本システムでは、TfidfVectorizer(scikit-learn)を用い、n-gramの範囲を1から2(unigramおよびbigram)に設定している。これは、単語単体での出現頻度(unigram)に加えて、連続する2単語(bigram)による文脈的特徴の補足を目的としたものである。たとえば、単語「中」単体では意味が曖昧になるが、「授業-中」や「昼食-中」などの2語連結により、より具体的な意味を捉えることが可能になる。また、日本語の形態的特徴に鑑み、n-gram抽出前にはMeCabをベースとした形態素解析(fugashiライブラリ)を用いてテキストをトークン化している。対象とする品詞は、「名詞」「動詞」「形容詞」に限定しており、助詞・助動詞・記号類などのノイズ語は除外している。このn-gramベースの特徴抽出により、TF-IDF計算においても単語の意味的連続性を捉えた分析が可能となり、より精度の高い高頻度語抽出や重要語ランキングの提示が可能となる。
分析
共通頻出語、動画ごとのTF-IDF上位語、レベル語
共通頻出語
共通頻出語は、再生リスト内のすべての動画に共通して頻出する語である。例えば料理関連の再生リストであれば、調理器具や手順、食材に関する語が共通頻出語として想定される。これらの語は再生リストの動画を理解するためには必須の語であり、学習者のレベルによらず、知っておく必要のある語である。
全動画に出現する名詞・動詞・形容詞の出現回数を計算し、上位20語を提示する。
動画ごとのTF-IDF上位語
次に、各動画に特徴的な語の提示を目的として、動画ごとのTF-IDF上位語を提示する。この項目の目標は
TF-IDF(Term Frequency-Inverse Document Frequency)分析をscikit-learnライブラリを用いて実施し、各動画において頻度や独自性に基づく重要な語彙を抽出する。
TF-IDFは、自然言語処理や情報検索において広く用いられている統計的指標であり、文書群の中から各文書を特徴付ける重要な単語を抽出するための尺度である。TF-IDFを用いることで、文書集合全体で頻繁に現れる一般的な単語よりも、ある特定の文書内でのみ頻出する特徴的な単語に高い重みを付与し、各文書を効果的に特徴付けることが可能となる。
分析結果から除外する語(ストップワード)
TF-IDF分析においては、頻出するものの文法的に意味を持たない語(例:「する」「ある」「です」「こと」など)が上位に入ることがある。こうした学習者の語彙習得に寄与しないと考えられる語や、ひらがな1文字、数字、記号といった要素をストップワードとしてあらかじめ除外した。これにより、学習に不要な語彙の影響を排除し、有用な語彙に焦点を当てた分析が可能となる。
加えて、YouTube字幕情報においてBGMが「[音楽]」として表示されるため、”[” 、“]”、 “音楽”をストップワードに追加した。
動画ごとのTF-IDF上位語の抽出例は表のとおりである。 難易度一致語(TF-IDF上位100語から)
難易度一致語は、各動画に特徴的な語のうち、学習者のレベルに応じた語を提示するものである。
各動画のTF-IDFの上位100語のうち、語彙表の当該レベルに一致する語を提示する。難易度一致語はユーザーがレベルを切り替えることで表示される語が変化する部分である。
分析例
パレ・ド・Z~おいしさの未来~
クローズアップ現代
まとめ:システムの処理フロー
- URLの入力と動画データ取得:学習者が選択したYouTube動画または再生リストのURLを入力すると、YouTube Data APIを用いて動画の字幕情報を取得する。再生リストの場合、システムは全ての動画を自動的に展開して処理する。
- 字幕データの抽出と前処理:取得した字幕テキストを日本語形態素解析ライブラリMeCabで解析し、名詞、動詞、形容詞のリストを作成する。
- TF-IDF分析:動画コンテンツから抽出したテキストデータに対してTF-IDF分析を行い、各動画に特有な重要語彙を数値的に評価し、優先順位を付ける。
- 語彙レベルのマッチングと抽出:学習者がシステムに申告した自身の日本語レベルに基づいて、分析された語彙リストから適切な難易度の語彙を選定する。
- 結果の表示と学習支援:選定された重要語彙および文脈を示す例文を学習者に提示し、選んだコンテンツの視聴前後で効率的な語彙学習を可能にする。
本システムのこの体系的かつ技術的なアプローチにより、個々の学習者の言語スキルに適した語彙や文法が提供され、理解度や学習意欲の向上、自律的な学習成果が期待できる。